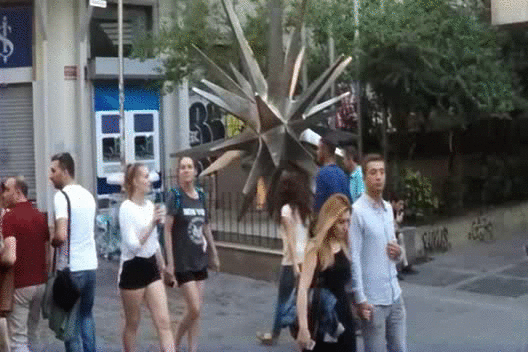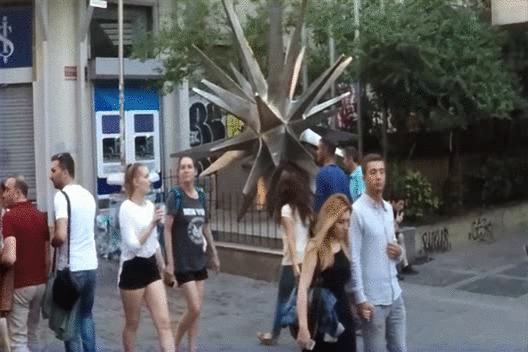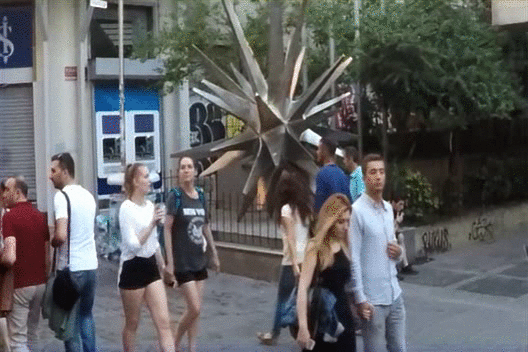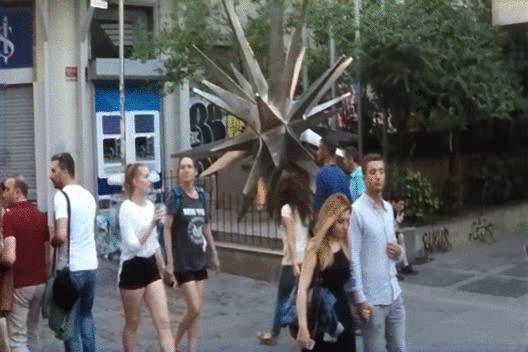|
The hardware challenges associated with light-field(LF) imaging has made it difficult for consumers to access
its benefits like applications in post-capture focus and aperture control. Learning-based techniques which solve
the ill-posed problem of LF reconstruction from sparse (1, 2 or 4) views have significantly reduced the
requirement for complex hardware. LF video reconstruction from sparse views poses a special challenge as acquiring
ground-truth for training these models is hard. Hence, we propose a self-supervised learning-based algorithm for
LF video reconstruction from monocular videos. We use self-supervised geometric, photometric and temporal
consistency constraints inspired from a recent self-supervised technique for LF video reconstruction from stereo
video. Additionally, we propose three key techniques that are relevant to our monocular video input. We propose
an explicit disocclusion handling technique that encourages the network to inpaint disoccluded regions in a LF
frame, using information from adjacent input temporal frames. This is crucial for a self-supervised technique as
a single input frame does not contain any information about the disoccluded regions. We also propose an adaptive
low-rank representation that provides a significant boost in performance by tailoring the representation to each
input scene. Finally, we also propose a novel refinement block that is able to exploit the available LF image data
using supervised learning to further refine the reconstruction quality. Our qualitative and quantitative analysis
demonstrates the significance of each of the proposed building blocks and also the superior results compared to
previous state-of-the-art monocular LF reconstruction techniques. We further validate our algorithm by reconstructing
LF videos from monocular videos acquired using a commercial GoPro camera.
|